碎碎念 作为一名 CS 专业的学生,拥有一套以自己域名后缀结尾的邮箱(如 me@yanchang.cc)是种刚需。它不仅在 GitHub Commit Log 里看起来更酷,也是展示个人品牌的绝佳方式。 起初我考虑过在自己的 Linux VPS 上手搓 自建邮箱服务器,但是真正的阻力来自于现代互联网
 发布于 2026-01-28
发布于 2026-01-28
![[技巧] PhotoPrism 缺失“全选”功能?一行代码实现批量审核/删除](/upload/39b18db4-77c2-4f4c-98ea-5a7266840ad6_%E5%89%AF%E6%9C%AC.jpeg)
碎碎念 之前自己在服务器上部署了 PhotoPrism 来管理大量的照片。体验总体不错,但在进行照片审核或整理归档时发现一个非常反人类的设计:目前的版本竟然没有“全选(Select All)”按钮! 当页面上有成百上千张照片需要批量通过审核或删除时,手动一个一个点击复选框简直是折磨。并且在处理的时候
发布于 2026-01-28

背景与痛点 我把博客部署在了家里的服务器上。但众所周知,家庭宽带一般都会封锁 80 和 443 端口。之前我只能被迫使用 8091 这种非标准端口(例如 https://www.yanchang.cc:8091)来访问,不仅域名后面带着个“小尾巴”不美观,而且对访客也不太友好。主要是给别人看的时候就
发布于 2026-01-27
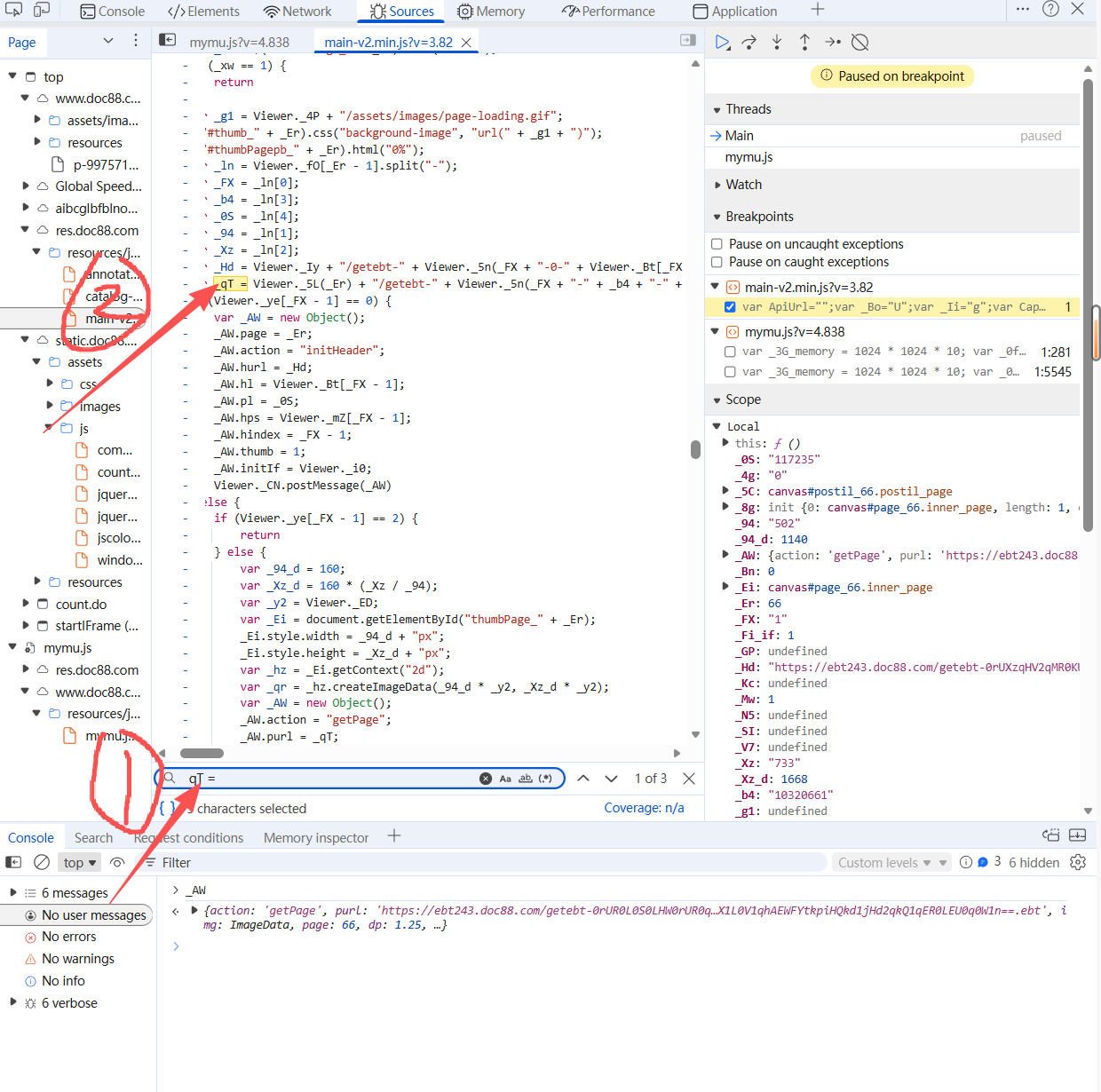
此文章为求助文章,所以很多操作的原因不解释,只给出操作步骤。 求助!!! 求助!!! 谁可以看一下canvas的照片解密逻辑,我没有看懂这个机密逻辑 网站URL(base64) aHR0cHM6Ly93d3cuZG9jODguY29tL3AtOTk3NTcxMDc0MTM2Ni5odG1s 请求参数
发布于 2026-01-21

碎碎念 万物皆可OpenWrt,之前修好的红米路由器,一直放着没怎么管过他,现在今天有时间给他拿出来倒腾一下。因为我的工位附近实在是没有RJ45网口了,所以只能是让路由器去连接无线校园网,将无线网作为wan口,也就是所谓的WISP (Wireless Internet Service Provide
发布于 2026-01-18
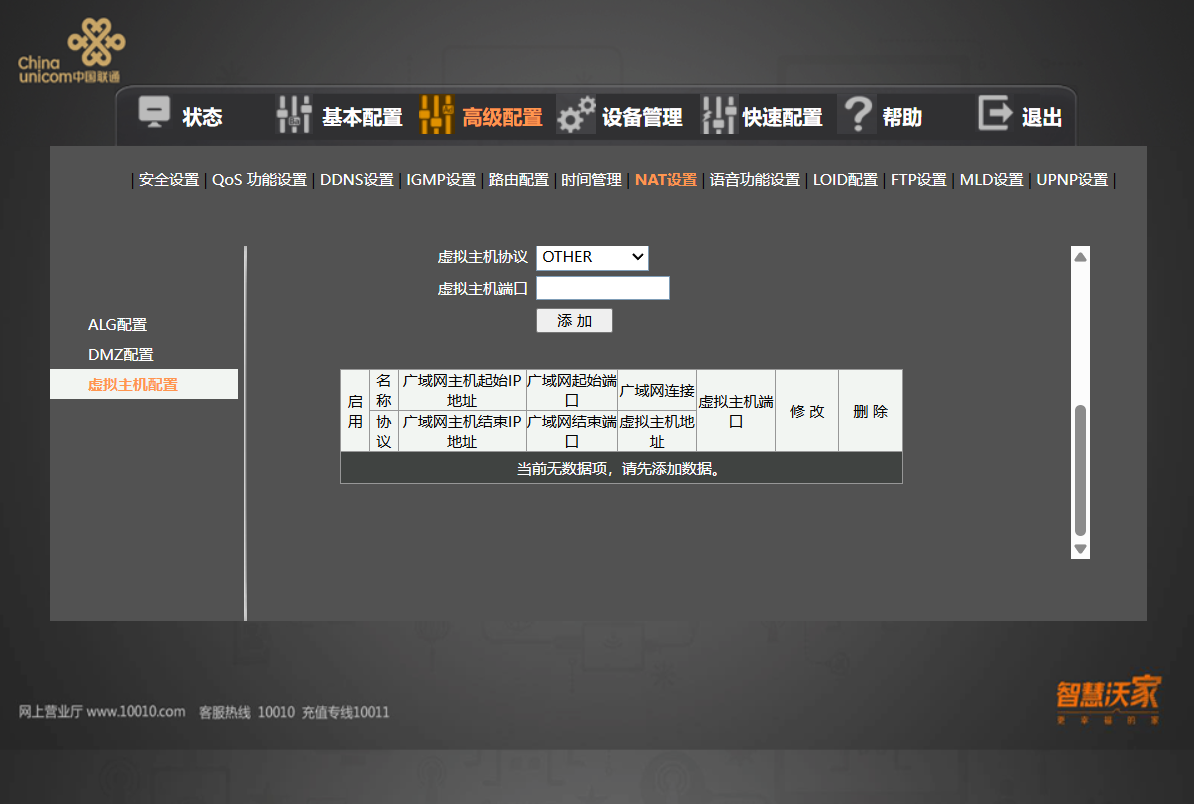
碎碎念 对于每一个在家里托管服务的 HomeLab 玩家来说,公网 IPv4 是最宝贵但也最脆弱的资源。 这一年多来,我利用家庭宽带搭建了自己的博客和开发环境。架构很标准:Linux 服务器 + Nginx + DDNS(动态域名解析) + 路由器端口转发。这套方案一直运行得很稳定,直到昨天,我突然
发布于 2026-01-17

🕒 背景:倒计时48小时的“渡劫” 最近这两天,课题组的气氛那是相当焦灼。一边是一个大项目的结题,另一边是新项目的开题,两个Deadline撞车,必须在48小时内全部搞定。 老板一声令下,全员进入“战时状态”,通宵熬夜是跑不掉了。但最搞心态的不是写本子,而是那些极其繁琐、重复、毫无技术含量但又必须
发布于 2026-01-09
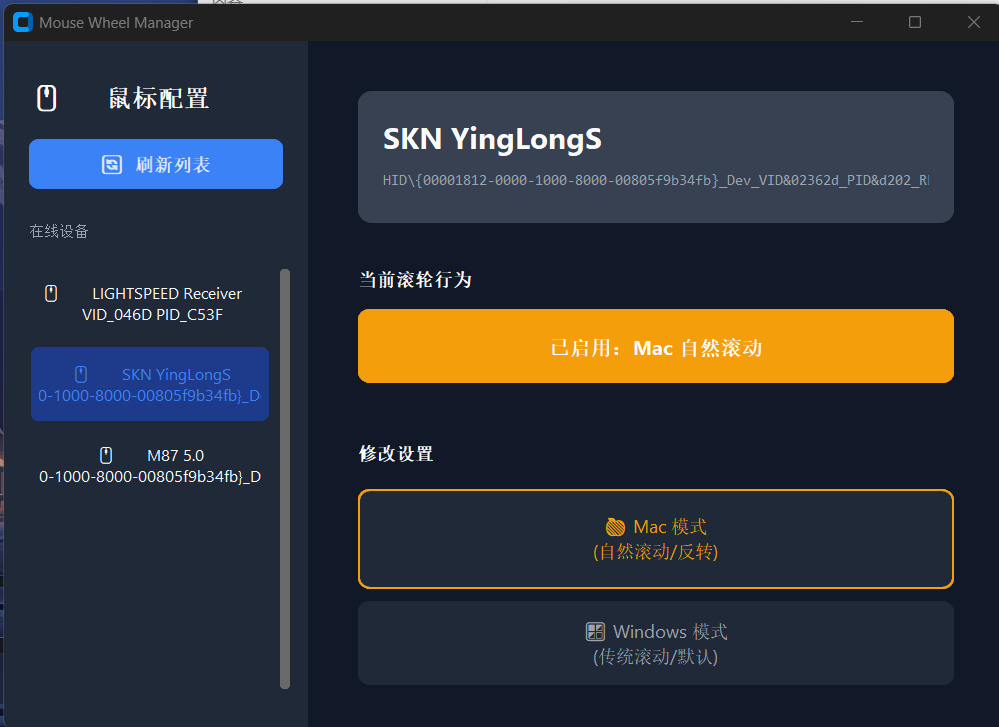
🚩 背景:当“板载内存”遇到“双系统” 作为一名研究生,我的日常工作流经常需要在 macOS 和 Windows 之间切换。我目前使用的是 SKN 应龙 鼠标。这款鼠标有一个很好的特性是“板载内存”,可以保存 DPI 和按键设置。 为了配合 macOS 的“自然滚动”习惯,我直接在鼠标的板载配置里
发布于 2026-01-07
![[故障排查] Windows 11 移动热点无法获取 IP 及无网络问题的深度分析与解决](/upload/image-Arpd.png)
碎碎念 最近发现我的 MiniPC (Windows 11) 开启移动热点后出现了一个奇怪的现象: 手机可以搜索到热点信号。 输入密码后可以通过验证。 故障点:连接过程一直卡在“正在连接”或“正在获取 IP 地址”,最终无法连接。 本文记录了从排查硬件、分析协议层到最终解决系统的完整 Debug 过
发布于 2026-01-03
碎碎念 因为实验室打印机扫描文件很麻烦,因为插入U盘总是有格式问题,所以看到打印机还有一个功能是扫描到网络文件夹,因此可以设置在局域网环境下进行设置共享文件服务器来实现,将自己电脑设置为服务端,打印机设置为客户端,实现将扫描件直接发送到自己电脑上。 因为我有两种电脑,因此在这里写两类电脑,分别为MA
发布于 2026-01-02

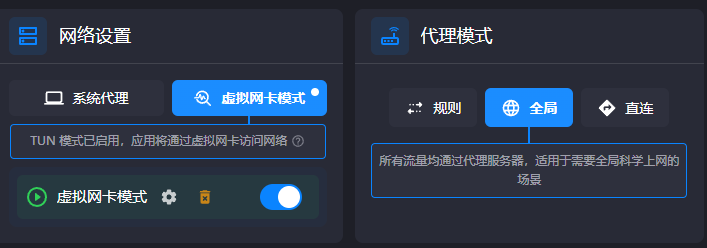
1. 方案概述 由于实验室当前并没有可以供学生使用的网络接口,因此当前的方案使用windwos电脑作为中转。 本方案旨在通过一台 Windows 电脑作为主网关,利用 Clash 的 TUN 模式接管系统流量,并通过网络共享 (ICS) 功能,将处理后的流量通过网线传输给无线路由器。 最终效果:连接
发布于 2025-12-10
